The problem
Suppose you have a Python script worker.py performing some long computation. Also suppose you need to perform these computations several times for different input data. If all the computations are independent from each other, one way to speed them up is to use Python’s multiprocessing module.
This comes down to the difference between sequential and parallel execution. Suppose you have the tasks A, B, C and D, requiring 1, 2, 3 and 4 seconds, respectively, to complete. When ran sequentially, meaning one after the other, you’d need 10 seconds in order for all tasks to complete, whereas running them in parallel (if you have 4 available CPU cores) would take 4 seconds, give or take, because some overhead does exist.
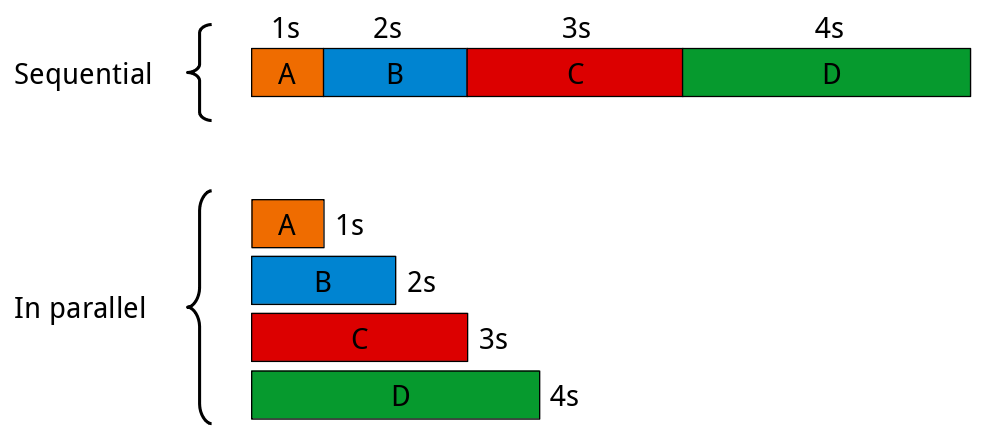
Before we continue, it is worth emphasizing that what is meant by parallel execution is each task is handled by a separate CPU, and that these tasks are ran at the same time. So in the figure above, when tasks A, B, C and D are run in parallel, each of them is ran on a different CPU.
The worker script
Let us see a very simple example for worker.py; remember that it performs long computations:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
import sys
import time
def do_work(n):
time.sleep(n)
print('I just did some hard work for {}s!'.format(n))
if __name__ == '__main__':
if len(sys.argv) != 2:
print('Please provide one integer argument', file=sys.stderr)
exit(1)
try:
seconds = int(sys.argv[1])
do_work(seconds)
except Exception as e:
print(e)
worker.py fails if it does not receive a command-line argument that can be converted to an integer. It then calls the do_work() method with the input argument converted to an integer. In turn, do_work() performs some hard work (sleeping for the specified number of seconds) and then outputs a message:
1
2
$ python worker.py 2
I just did some hard work for 2s!
(Just in case you were wondering, if do_work() is called with a negative integer, then it is the sleep() function that complains about it.)
The main script
Let us now see how to run worker.py from within another Python script. We will create a file main.py that creates four tasks. As shown in the figure above, the tasks take 1, 2, 3 and 4 seconds to finish, respectively. Each task consists in running worker.py with a different sleep length:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
import subprocess
import multiprocessing as mp
from tqdm import tqdm
NUMBER_OF_TASKS = 4
progress_bar = tqdm(total=NUMBER_OF_TASKS)
def work(sec_sleep):
command = ['python', 'worker.py', sec_sleep]
subprocess.call(command)
def update_progress_bar(_):
progress_bar.update()
if __name__ == '__main__':
pool = mp.Pool(NUMBER_OF_TASKS)
for seconds in [str(x) for x in range(1, NUMBER_OF_TASKS + 1)]:
pool.apply_async(work, (seconds,), callback=update_progress_bar)
pool.close()
pool.join()
The tasks are ran in parallel using NUMBER_OF_TASKS (4) processes in a multiprocessing pool (lines 20-26). When we refer to the tasks being ran in parallel, we mean that the apply_async() method is applied to every task (line 23). The first argument to apply_async() is the method to execute asynchronously (work()), the second one is the argument for work() (seconds), and the third one is a callback, our update_progress_bar() function.
The work() method (lines 10-12) calls our previous script worker.py with the specified number of seconds. This is done through the Python subprocess module.
As for tqdm, it is a handy little package that displays a progress bar for the number of items in an iteration. It can be installed through pip, conda or snap.
Parallelization in practice
Here is the output of our main.py script:
1
2
3
4
5
6
7
8
9
10
$ python main.py
0%| | 0/4 [00:00<?, ?it/s]
I just did some hard work for 1s!
25%|███████████████ | 1/4 [00:01<00:03, 1.02s/it]
I just did some hard work for 2s!
50%|██████████████████████████████ | 2/4 [00:02<00:02, 1.02s/it]
I just did some hard work for 3s!
75%|█████████████████████████████████████████████ | 3/4 [00:03<00:01, 1.01s/it]
I just did some hard work for 4s!
100%|████████████████████████████████████████████████████████████| 4/4 [00:04<00:00, 1.03s/it]
As you can see, the four tasks finished in about 4 seconds, meaning that the execution of the worker.py script has successfully been parallelized.
The next post Multiprocessing in Python with shared resources iterates on what we have just seen in order to show how we can parallelize external Python scripts that need to access the same shared resource.
Further reading
subprocess(Python documentation)multiprocessing(Python documentation)- Parallel processing in Python (Frank Hofmann on stackabuse)
multiprocessing– Manage processes like threads (Doug Hellmann on Python Module of the Week)
Comments powered by Disqus.